
Automating Data Engineering Pipelines with Apache Airflow
Using Apache Airflow to Automate and Orchestrate Data Engineering Tasks in Python

One of the most important parts of a data engineering pipeline is orchestration. Orchestrations refers to the process of automating a process (in this case a pipeline) to run on scheduled intervals (or on triggers). This is particularly important in the data landscape as we have new sources of data quite frequently and making sure that your data engineering pipeline consumes and processes that data frequently is crucial to any data-oriented business.
In this tutorial, we'll automate the process of scraping stock data and loading it into Google BigQuery using Apache Airflow and Astronomer. We have built and dockerized the script to scrape stock data in the previous articles, so we will focus on automating the process to run at scheduled intervals using Airflow in this article.
You can download the code for this article from here
Introduction
Apache Airflow is an open-source platform for workflow automation, and Astronomer provides managed Airflow services. Airflow is the most common orchestration tool used in industry, with Mage and Prefect. Apache Airflow allows us to define any workflow in Python code, no matter the complexity and is used by companies worldwide including tech giants like Adobe. Some of the popular usecases include:
Business Operations
ETL/ELT
Infrastructure Management
MLOps
Prerequisites
Before we begin, ensure you have the following:
An Astronomer account (Sign up at https://www.astronomer.io/)
Access to Google Cloud Platform (GCP) with BigQuery enabled
Followed my previous articles on building the scraper (1 and 2) and dockerizing the application (here)
Setting Up Your Environment
Install Astronomer CLI
Make sure you have Astronomer CLI installed by following their documentation
Create a New Airflow Project
Use the Astronomer CLI to create a new Airflow project. Navigate to where you want to create a the project, run:
astro dev init stock_scraperProject Structure
This will create a lot of different files for you similar to below:
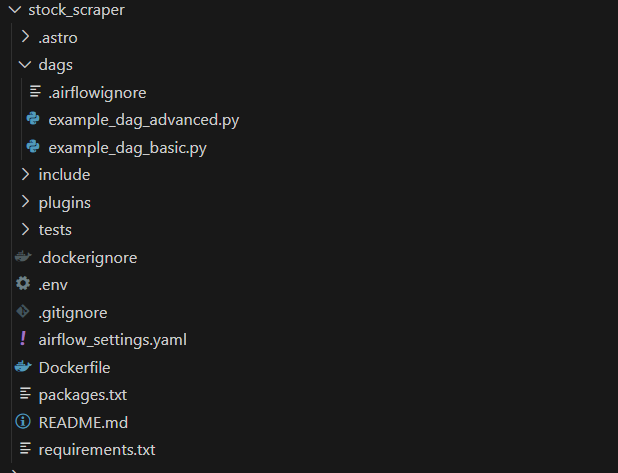
Note that it already creates two DAGs for you (which is basically the workflows that we automate in Airflow). Most of the files are not related to what we are going to do. You have to do the following:
Delete the existing dags
Create a
scrapersfolder inside thedagsfolderMove the
stock_data_scraper.pywe created in previous articles to this folderCreate a new empty
stock_scraper_dag.pyfile in thedagsfolderCreate two
__init__.pyfiles. One indagsfolder and one indags/scrapersfolder
Your new project structure should look like this:
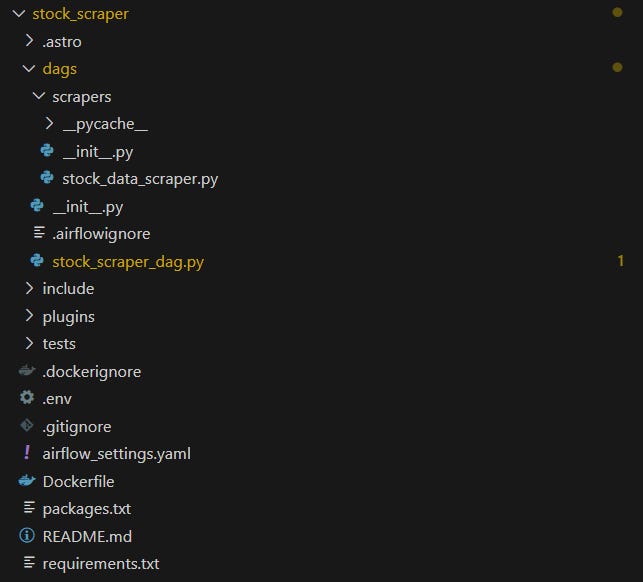
What is a DAG?
A Directed Acyclic Graph (DAG) is a concept borrowed from mathematics. In the context of Apache Airflow, a DAG is a collection of all the tasks you want to run, organized in a way that reflects their relationships and dependencies. So, basically a DAG is a script that contains one or more tasks inside it that can be run on scheduled intervals and can have dependencies within them such as one task runs only if the previous tasks successfully finishes.
Writing your first DAG
We will write our first dag (stock_scraper_dag.py) whose goal is to run the stock_data_scraper.py code on a scheduled basis.
Define the imports
We start by defining our imports. The DAG represents a workflow and PythonOperator allows us to execute Python functions as tasks within our DAG. Other imports include datetime for scheduling, our scraper and loading the environment variables.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
from scrapers.stock_data_scraper import StockDataScraper
import os
from dotenv import load_dotenv
load_dotenv()Note: One thing to change definitely is to remove the data fetching from the stock_data_scraper.py file as we are now importing it and will fetch the data in this file. If the fetching part is still there, even importing would trigger it as well.
Defining the Arguments
Then, we define a dictionary containing default arguments for our DAG. These arguments specify settings such as the owner of the DAG, the start date, email configuration for notifications, and retry behavior.
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 3, 25),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
}Creating the DAG Object
We then create the DAG object, where we provide the DAG ID, default arguments, description, and schedule interval. In this case, the DAG will run daily.
dag = DAG(
'stock_data_scraper',
default_args=default_args,
description='Scrape stock data and load it into BigQuery',
schedule_interval='@daily',
)Defining our function
Now, we define our function which defines and runs our scraper:
def scrape_and_load_data():
project_id = os.environ["PROJECT_ID"]
dataset_id = os.environ['DATASET_ID']
table_id = os.environ['TABLE_ID']
scraper = StockDataScraper(project_id, dataset_id, table_id)
scraper.fetch_data()
scraper.create_bigquery_table()
scraper.process_data()
scraper.load_data_to_bigquery()
Running our DAG
Finally, we would run our dag by defining a task using the PythonOperator within the above defined dag:
with dag:
scrape_task = PythonOperator(
task_id='scrape_and_load_data',
python_callable=scrape_and_load_data,
)Environment Variables and Requirements
Make sure to add the environment variables in the .env file along with the requirements in the requirements.txt file. Although it is not best practice, we would store our json key for BigQuery for demonstration purposes.
Start the Airflow Server
Now, we can start our server by running the following command:
astro dev startYou will need to wait a bit so that it can finish. The output would be something like this:
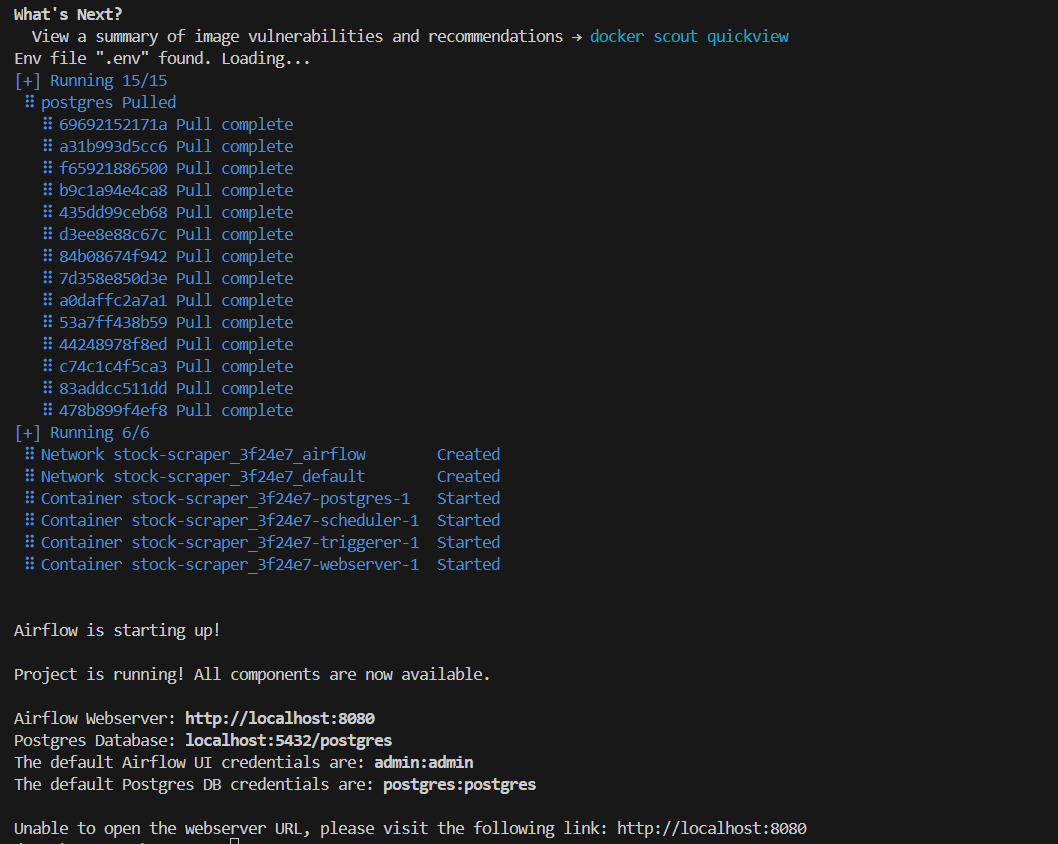
You can go to the given url and login with the credentials. You will see the UI as below:
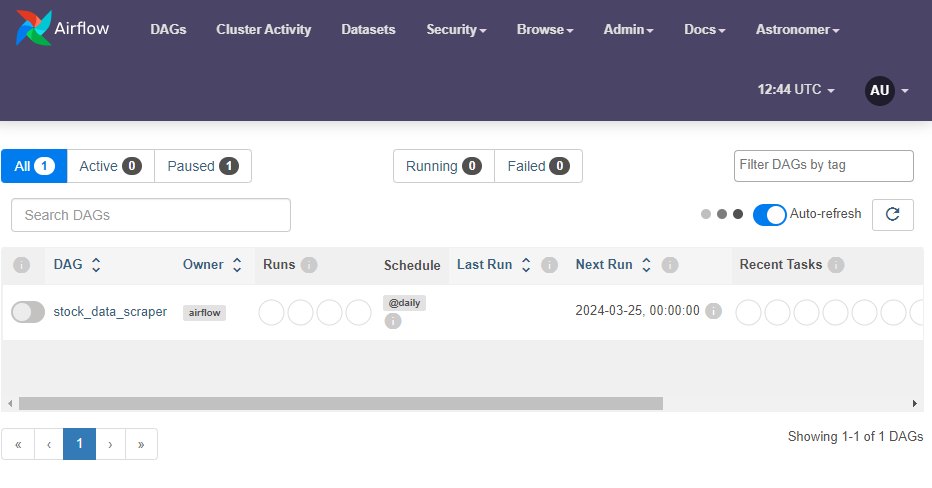
Currently it is not active, but we can click on it. Click on the arrow below to run it too:
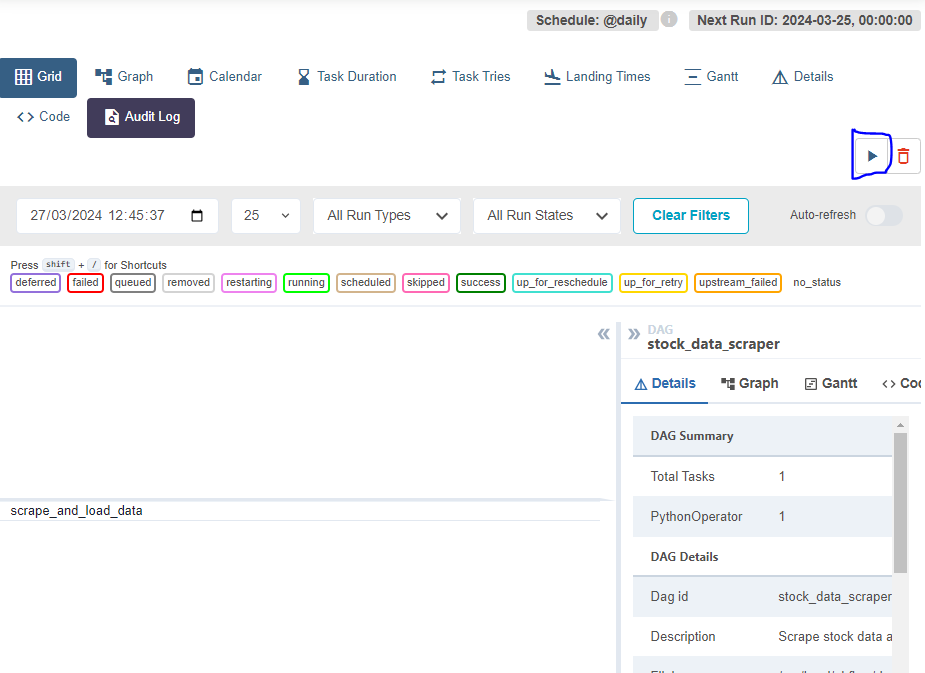
It should successfully run as follows:
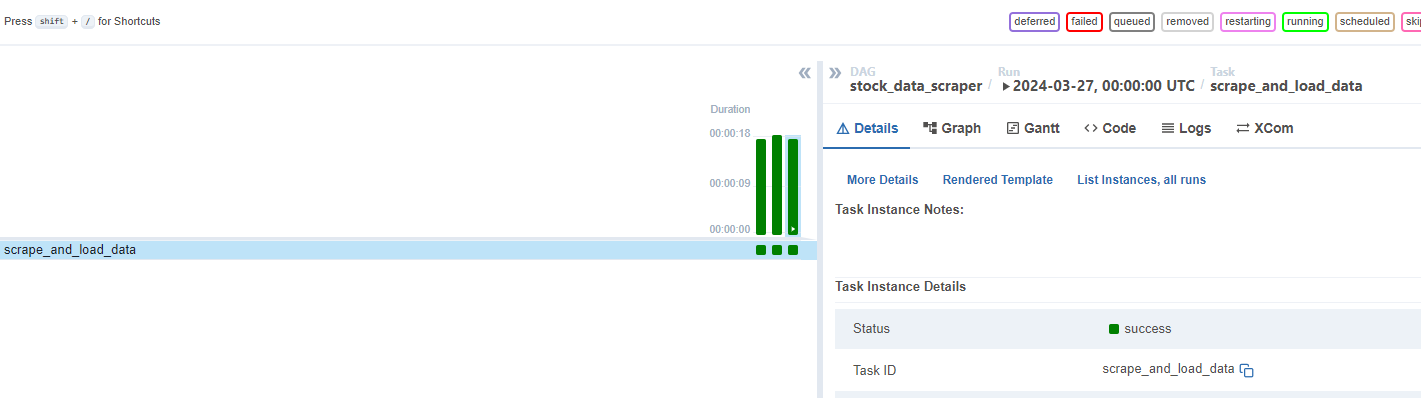
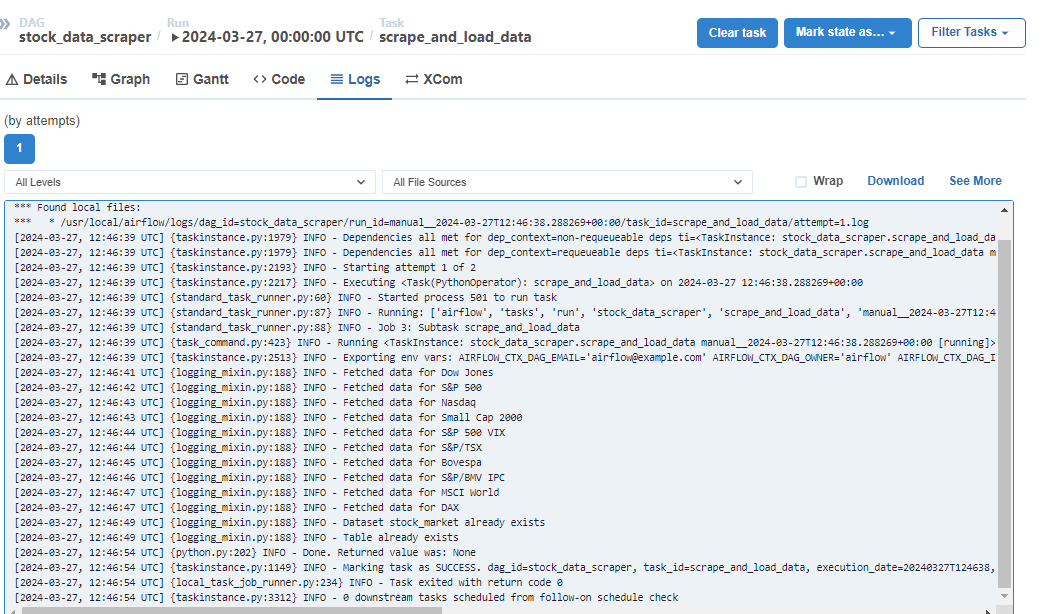
Feel free to verify the data in BigQuery too. You can check the logs too. If the tab is not there, click on Graph and then the rectangle in the grid, it should show up.
Conclusion
In this tutorial, we've gone through a step-by-step process of setting up an Apache Airflow environment to automate a data scraping task. We've covered the basics of Airflow, how to write a DAG, and how to schedule and run the DAG. With these skills, you should be able to start automating your own data engineering pipelines. Remember, practice is key in mastering any new technology or tool. Happy coding!