
Building an end-to-end data engineering project for your portfolio
Build your first data pipeline, from scraping the data using Python to orchestrating it through Airflow, this guide will cover it all

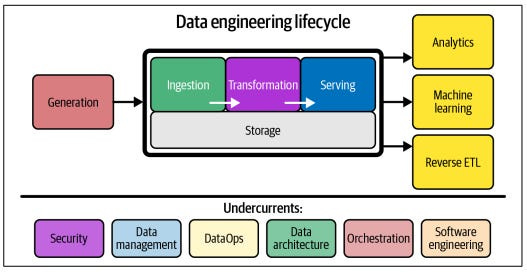
In today's data-driven world, the ability to efficiently manage and analyze data is crucial for businesses to thrive. Data engineering plays a pivotal role in this process, encompassing the collection, storage, processing, and serving of data. In this article, we'll explore a step-by-step approach to building a successful data engineering project, covering everything from data acquisition to serving it to end-users. I have linked all the individual articles under each heading for the information needed to build this project from scratch.
You can find the code for this whole project here
Getting the Data
The first step in any data engineering project is to acquire the necessary data. Identifying relevant data sources and devising a plan to extract data from them is key. In our project, we focused on extracting stock market data from investing.com. Using Python, we developed a web scraping script to extract the desired data and store it locally in a CSV file. This initial phase lays the foundation for the entire project by ensuring that we have access to the data needed for analysis.
Link to the article: https://open.substack.com/pub/nouman10/p/a-comprehensive-guide-to-web-scraping
Dumping the Data to BigQuery
Once we have collected the data, the next step is to store it in a scalable and easily accessible database. For our project, we chose Google BigQuery for its ability to handle large datasets efficiently. By leveraging BigQuery's capabilities, we were able to dump the scraped data into a structured format that could be easily queried and analyzed. This step ensures that our data is stored securely and is readily available for downstream tasks such as data analysis and machine learning.
Link to the article: https://open.substack.com/pub/nouman10/p/leveraging-python-to-transfer-data
Dockerizing the Application
To ensure that our data engineering pipeline is easily deployable and reproducible, we containerized our application using Docker. Docker allows us to package our Python web scraper and its dependencies into a lightweight container, making it easy to deploy across different environments. By containerizing our application, we ensure consistency and reliability, regardless of the underlying infrastructure. This step simplifies the deployment process and facilitates collaboration among team members.
Link to the article: https://open.substack.com/pub/nouman10/p/learning-to-deploy-your-first-docker
Orchestration through Airflow
Automation is key to maintaining a smooth and efficient data pipeline. In our project, we used Apache Airflow for orchestration, allowing us to automate the execution of our data pipeline on scheduled intervals. By defining Directed Acyclic Graphs (DAGs) in Airflow, we were able to schedule tasks such as data extraction, transformation, and loading (ETL) to run automatically at predefined times. This automation reduces the need for manual intervention, ensuring that our data pipeline operates reliably and consistently.
Link to the article: https://open.substack.com/pub/nouman10/p/automating-data-engineering-pipelines
Serving the Data through API
The final stage of our data engineering project involves serving the data to end-users in a consumable format. To achieve this, we used FastAPI to create a RESTful API that exposes endpoints for accessing the data stored in BigQuery. By leveraging FastAPI's capabilities, we were able to create endpoints that allow users to query the data based on specific criteria and filters. This API serves as the interface between our data pipeline and end-users, enabling them to access the latest stock market data in real-time.
Link to the article: https://open.substack.com/pub/nouman10/p/serving-data-using-fastapi-with-google

Conclusion
Building a successful data engineering project requires careful planning, execution, and iteration. By following the steps outlined in this article – from acquiring the data to serving it to end-users – organizations can develop robust data pipelines that empower them to make informed decisions and drive business growth. With the right tools and techniques, data engineering can unlock valuable insights from raw data, paving the way for innovation and competitive advantage in today's digital landscape.